本文共 4099 字,大约阅读时间需要 13 分钟。
紧接上一篇!!
(二)抢占和进程上下文
上下文切换,就是从一个可执行进程切换到另一个可执行进程,由定义在kernel/sched.c中的context_switch()函数处理,该函数主要完成两项基本工作:
1:调用声明在asm/mmu_context.h中的switch_mm(),该函数负责把虚拟内存从上一个进程映射切换到新进程中。2:调用声明在asm/system.h文件中的switch_to()函数,该函数负责从上一个进程的处理器状态切换到新进程的处理器状态。这包括保存,恢复栈信息和寄存器信息,还有其他任何与体系结构相关的信息,都必须以每一个进程为对象进行管理和保存。
下面我们看一下函数context_switch()的代码:
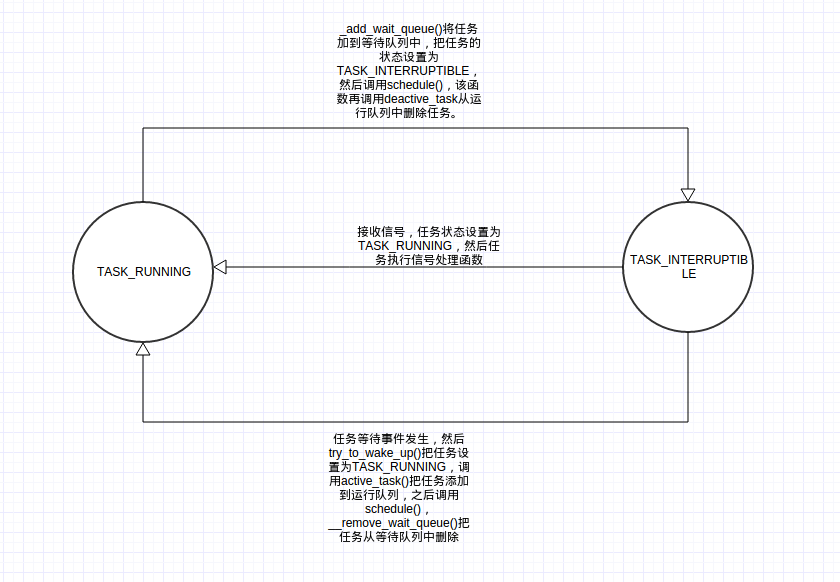
/* * context_switch - switch to the new MM and the new * thread's register state. * * context_switch - 切换到一个新的MM(内存)和新的进程 * 的寄存器状态 */static inline voidcontext_switch(struct rq *rq, struct task_struct *prev, struct task_struct *next){ struct mm_struct *mm, *oldmm; prepare_task_switch(rq, prev, next); trace_sched_switch(rq, prev, next); mm = next->mm; oldmm = prev->active_mm; /* * For paravirt, this is coupled with an exit in switch_to to * combine the page table reload and the switch backend into * one hypercall. */ arch_start_context_switch(prev); if (likely(!mm)) { next->active_mm = oldmm; atomic_inc(&oldmm->mm_count); enter_lazy_tlb(oldmm, next); } else switch_mm(oldmm, mm, next); if (likely(!prev->mm)) { prev->active_mm = NULL; rq->prev_mm = oldmm; } /* * Since the runqueue lock will be released by the next * task (which is an invalid locking op but in the case * of the scheduler it's an obvious special-case), so we * do an early lockdep release here: */#ifndef __ARCH_WANT_UNLOCKED_CTXSW spin_release(&rq->lock.dep_map, 1, _THIS_IP_);#endif /* Here we just switch the register state and the stack. */ switch_to(prev, next, prev); //切换处理器状态,并保存上一个进程的处理器状态 barrier(); /* * this_rq must be evaluated again because prev may have moved * CPUs since it called schedule(), thus the 'rq' on its stack * frame will be invalid. */ finish_task_switch(this_rq(), prev);} 下面我们来整体的看一下休眠和唤醒的函数调用和过程:
内核提供need_resched变量来表明函数是否需要重新进行一次调度,下面是用于访问和操作need_resched变量的函数。

在返回用户空间以及从中断返回的时候,内核也会检查need_reched标志,如果已被设置,内核会在继续执行之前调用调度程序。
每个进程都有一个need_resched标志,这是因为访问进程描述符内的数值比访问一个全局变量快。
1:用户抢占
内核即将返回用户空间的时候,如果need_resched标志被设置,会导致schedule()被调用,此时就会发生用户抢占。用户抢占在一下情况下发生:
1:从系统调用返回用户空间的时候 2:从中断处理函数返回用户空间的时候2:内核抢占
Linux完整的支持内核抢占,但是,由于内核抢占会出现一些安全性问题,那么,内核抢占时机的确定是相当重要的,那么什么时候进行重新调度是安全的呢?只要没有锁,内核进可以进行抢占。
Linux为了支持内核抢占,在thread_info中引入了preempt_count计数器。该计数器的初始值为0,每当使用锁的时候,该值加1,当释放锁的时候,该值减1,当该数值为0的时候,内核就可以抢占。当从中断返回内核空间的时候,内核就会检查need_resched标志和preempt_count计数器。如果need_resched标志被设置,并且preempt_count数值为0,调度程序就会被执行。
如果此时的preempt_count不为0,说明当前任务持有锁,所以抢占是不安全的。 这时,内核就会像通常那样直接从中断返回当前执行进程。如果当前执行进程持有的所有的锁都被释放了,preempt_count数值为0,此时,释放锁的代码就会检查need_resched标志是否被设置,如果被设置的话,就会调用调度程序。
内核抢占发生的时间:
1:中断处理程序正在执行,且返回内核空间之前2:内核代码再一次具有可抢占性的时候3:如果内核中的任务显示的调用schedule()函数4:如果内核中的任务阻塞
(二):实时调度策略
Linux提供了两种实时调度策略:SCHED_FIFO和SCHED_RR,而普通的,非实时的调度策略是SCHED_NORMAL。这些实时调度策略被是个特殊的实时调度器管理,定义在kernel/sched_rt.c中。1:SCHED_FIFO
这是一个先入先出的调度算法,他不使用时间片。处于可运行状态的SCHED_FIFO级进程会比任何SCHED_NORMAL进程都先得到调度。一旦一个SCHED_FIFO进程处于可执行状态,就会一直执行下去,只有更高优先级的SCHED_FIFO和SCHED_RR任务才能抢占SCHED_FIFO任务。如果有两个或多个同优先级的SCHED_FIFO级进程,他们会轮流执行,但是依然只有他们愿意让出处理器的时候才会退出。只要有SCHED_FIFO级进程在执行,其他级别较低的进程就只能等待他变为不可运行状态后才有机会执行。
2:SCHED_RR
SCHED_RR和SCHED_FIFO大体相同,只是 SCHED_RR级的进程在耗尽事先分配给他的时间后就不在继续执行了,也就是说SCHED_RR是带有时间片的SCHED_FIFO,这是一种实时轮流调度算法。当SCHED_RR任务耗尽他的时间片的时候,在同一优先级的其他实时进程被轮流调度。时间片只用来重新调度同一优先级的进程。对于SCHED_FIFO进程,高优先级进程总是立即抢占低优先级,但是低优先级决不能抢占SCHED_RR任务,即使他的时间片耗尽。
Linux的实时调度算法提供了一种软实时工作方式。软实时的含义是,内核调度进程,尽力使进程在他的限定时间到来之前运行,但内核不保证总能满足这些进程的要求。
实时优先级范围是从0到MAX_RT_PRIO-1。默认情况下,MAX_RT_PRIO为100,所以默认的实时优先级的范围是0-99.SCHED_NORMAL级进程的nice值共享了这个取值空间,他的取值范围是从MAX_RT_PRIO到(MAX_RT_PRIO+40)。也就是说,在默认情况下,nice值从-20到+19直接对应的是从100-139的实时优先级范围。
(三):与调度相关的系统调用
Linux提供了一个系统调用族,用于管理与调度程序相关的参数。下面我们来看一下系统调用。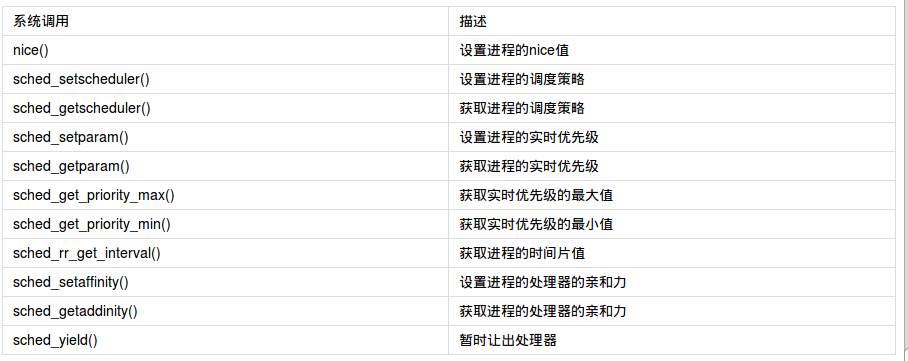
Linux调度程序提供强制的处理器绑定(processor affinity)机制。也就是说,他允许用户强制指定”这个进程必须在这些处理器上执行“。这种强制的亲和性保存在进程的task_struct结构中的cpus_allowed这个位掩码标志中。该掩码标志的每一位对应一个系统可用的处理器。默认情况下,所有的位都被设置,进程可以在系统中所有可用的处理器上执行。用户可以通过sched_setaffinity()设置不同的一个或几个位组合的掩码,而调用sched_getaffinity()则返回当前的cpus_allowed位掩码。
Linux通过sched_yield()系统调用,提供了一种让进程显示地将处理器时间让给其他等待执行进程的机制。